不得不说,Cursor 这类 AI 编码工具确实潜力巨大,堪称开发利器。
然而,现实中许多 AI 辅助项目却常常陷入困境,甚至走向崩溃。究其原因,无外乎三个“老大难”问题:
- AI 幻觉 (Hallucinations): 一本正经地胡说八道,生成不存在的库或错误代码。
- 错误循环 (Loop of errors): 在一个小错误上反复纠缠,无法自拔。
- 上下文感知缺失 (Context awareness): 缺乏对项目整体背景和要求的理解,导致生成内容偏离目标。
经历过这些“痛”之后,我摸索出了一套行之有效的系统方法,专门用于攻克这三大难题。我称之为——上下文边界方法 (Context Boundary Method)。
简单来说,就是为你的 AI 助手划定一个清晰的“知识边界”。

1. 上下文边界 = AI 的专属知识库
这套方法的核心在于构建一套完善的编码文档体系。在我每次启动新项目时,都会遵循以下文档结构:
- PRD (产品需求文档): 项目的蓝图和方向。
- Product Doc (产品需文档): 产品解决的痛点、出发点、解决方案路径
- App Flow Doc (应用流程文档): 用户交互的完整路径。
- Arch (技术架构文档): 项目的技术架构文档
- Tech Stack Doc (技术栈文档): 使用的技术和工具清单。
- Frontend Guidelines (前端规范): 统一的视觉和交互标准。
- Backend Structure (后端结构文档): 数据库、认证和核心逻辑。
- Stories (需求故事文档): 50个左右任务,项目的需求结合技术设计拆解的路线图
- Implementation Plan (实施计划): 详细的、分步骤的开发任务列表。
这些文档共同构成了 AI 进行开发工作的“知识库”。没有它们,AI 就像一个没头苍蝇,开发过程自然乱作一团。
我本地 App 开发的文档结构示例:
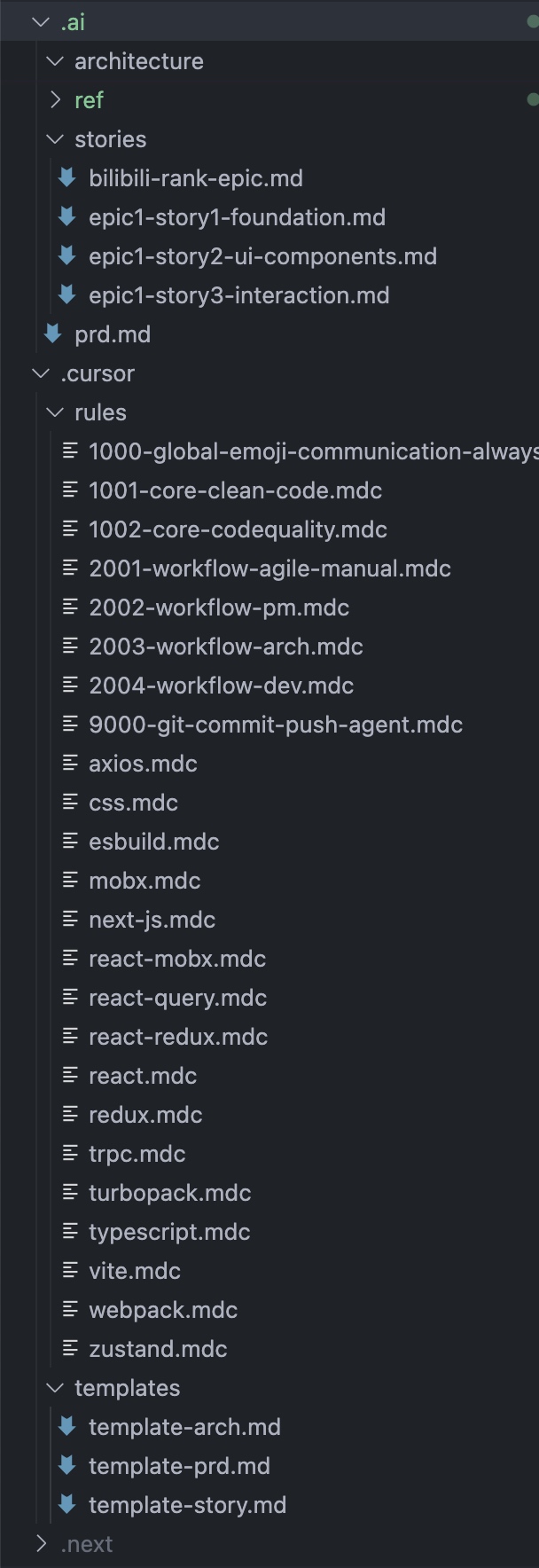
2. 善用工具,高效生成 AI 编码文档
你可能会问,准备这么多文档岂不是很费时?其实不然。我们可以借助 ChatGPT 或 CherryStudio 这类工具来辅助生成这些 AI 编码文档。
我个人常用 @CherryStudio,因为它本身就是为生成 AI 编码文档而设计的,支持 Claude、GPT-4o 和 Gemini 等多种模型,并且能与所有主流 AI 编码工具协同工作。在构建 MVP (最小可行产品) 的过程中,它确实为我节省了大量时间。
3. PRD (产品需求文档) = 项目的导航地图
在动工之前,一份清晰的产品需求文档(PRD)是必不可少的。它需要明确回答以下问题:
- 这是一款什么样的产品?
- 目标用户是谁?
- 它解决了什么核心问题?
- 哪些功能在范围内?哪些在范围外?
这份文档能确保 AI 始终聚焦于核心需求,而不是被你随时抛出的新想法带偏。
实战经验: 我开发了一个专门的 Agent,利用 Gemini 2.5 Pro 的超长上下文能力,与我深入讨论所有需求细节,最终生成详尽的 PRD 文档。
Agent 协助讨论和生成 PRD 的过程:

一次和 AI 真实互动沟通需求实现的记录截图
我开始沟通需求:

AI询问需求细节依赖,我提供信息:

最后完成需求沟通,输出全部 PRD 文档:
我通常会和 AI 讨论确定后,存放在项目路径下的 .ai/prd.md 文件中

最终将生成的 PRD 文档整合到项目初始化文件中:
4. App Flow Doc (应用流程文档) = 用户的完整旅程
这份文档需要用清晰、无歧义的自然语言,详细描述用户的整个使用流程:
- 每个界面展示什么?
- 用户如何从一个屏幕跳转到下一个屏幕?
- 关键操作(如登录、购买、发布)发生在哪个环节?
请务必具体! 不要只说“仪表盘”,而是要描述仪表盘里具体包含哪些元素和功能。这部分内容可以整合进 PRD 文档的“用户旅程 (User Journey)”模块。
5. 技术架构文档 = AI 的建造指南
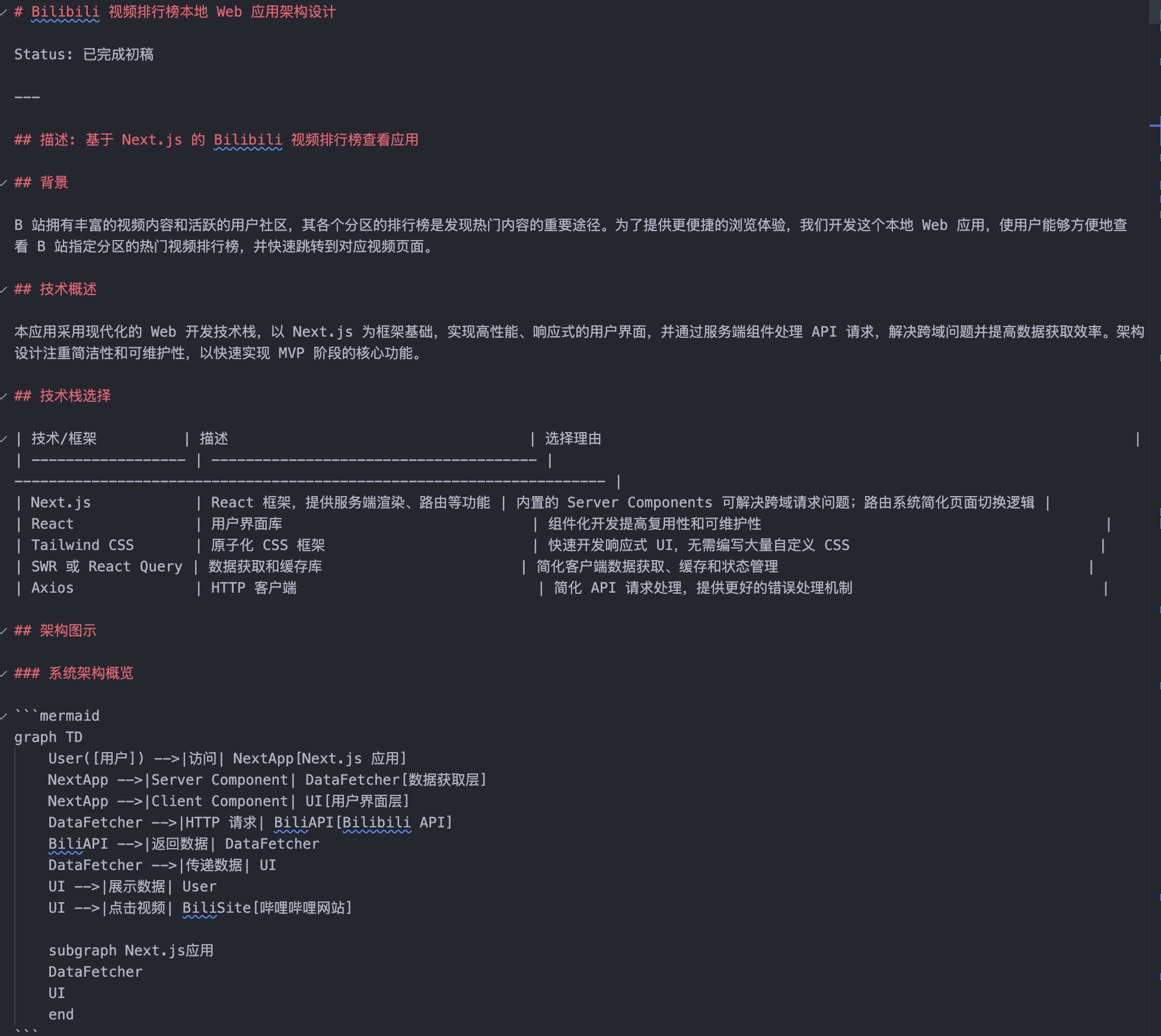
这部分是 AI 执行具体编码任务的技术依据,我通常会和 AI 讨论确定后,存放在项目路径下的 .ai/architecture/architecture.md 文件中。它主要包含以下三部分:
1) 技术栈文档 (Tech Stack Doc): 明确告知 AI 使用哪些技术进行构建。
- 框架 (Frameworks)
- API 接口
- 认证工具 (Auth tools)
- SDKs
- 各项技术的官方文档链接
这能有效避免 AI “幻觉”出虚假的库或错误的导入语句。
技术栈文档示例:
2) 前端规范 (Frontend Guidelines): 定义你的设计语言系统。 想要你的应用界面风格统一、视觉协调吗?那就必须教会 AI 你的设计语言。包括:
- 字体 (Fonts)
- 调色板 (Color palette)
- 间距系统 (Spacing system)
- 首选 UI 模式 (Preferred UI patterns)
- 图标集 (Icon set)
前端规范示例:
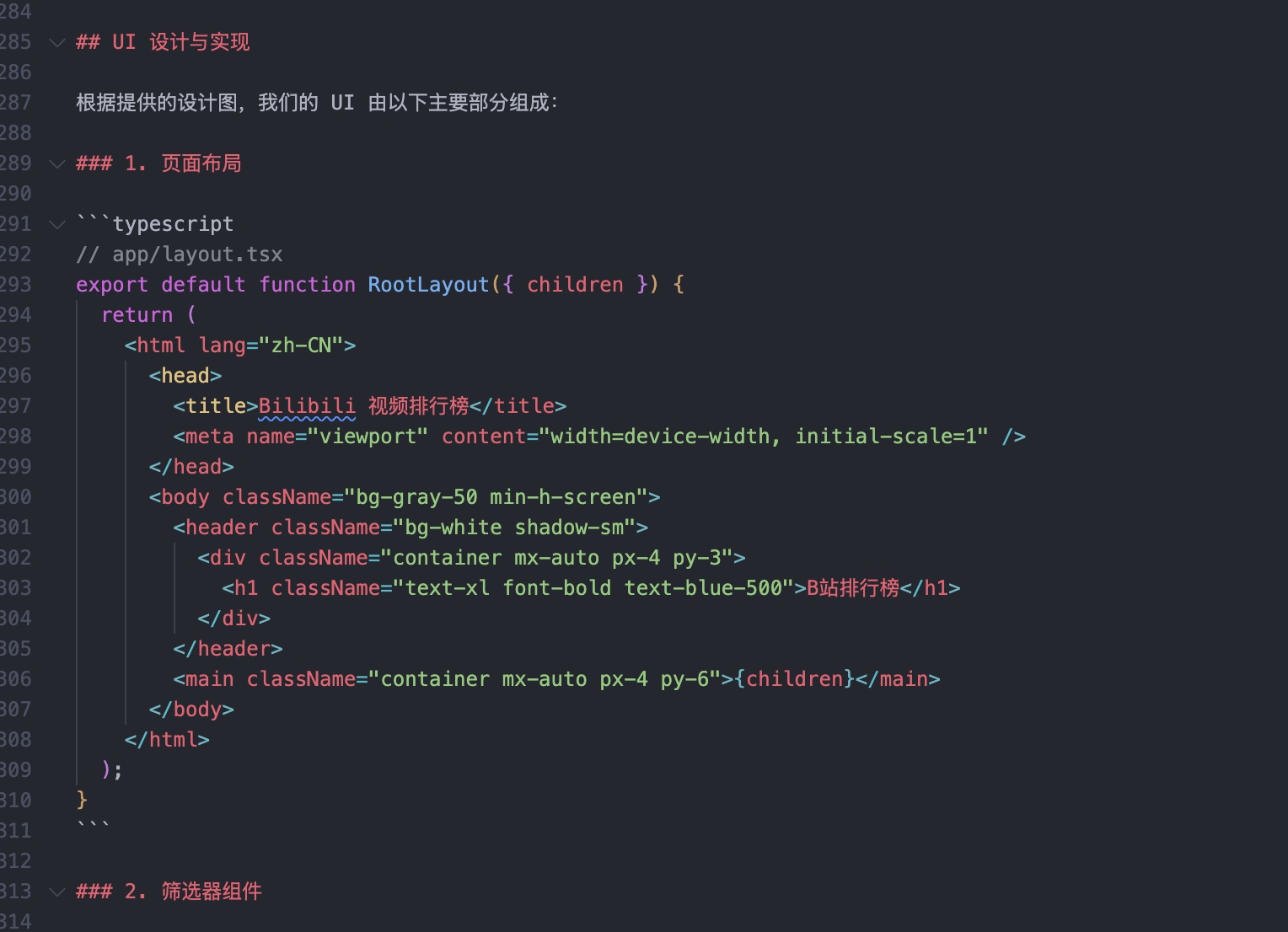
有了这些规范,像 Windsurf 或 Cursor 这样的工具才能生成整洁、统一的用户界面。
3) 后端结构文档 (Backend Structure Doc): 定义数据库和认证逻辑。
这份文档明确了:
- 数据表结构 (Tables + schema)
- 数据存储规则 (Storage rules)
- 认证流程 (Auth flows)
- 边缘情况处理 (Edge cases),例如重试或错误处理逻辑。
后端结构文档片段示例:

6. 实施计划 (Implementation Plan) = 按部就班的施工图
在我看来,这是整个文档体系中最核心、最强大的一环。
我会将整个应用的构建过程,拆解成 50 个以上清晰、明确的步骤。
每一个步骤,都是一个给 AI 的具体指令 (Prompt)。
然后,无论是 Cursor Agent 还是 Windsurf,都可以像一个初级开发者一样,按部就班、逐一完成这些任务。
实施计划(Story)示例:
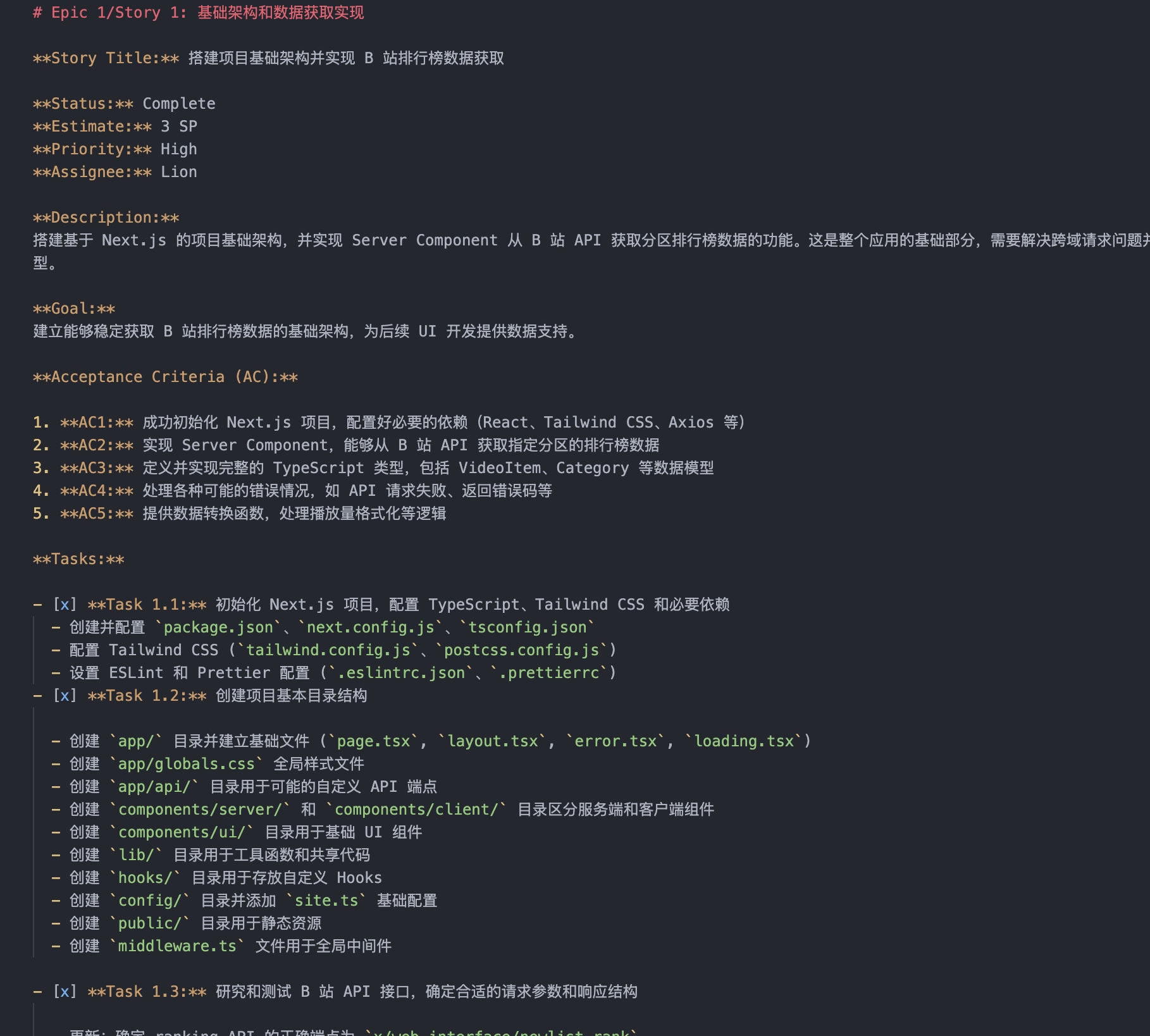
AI 根据实施计划执行任务:
7. 发布前的最终校验:代码/Story/审计
当 AI 完成编码任务后,千万别急着发布!
我的习惯是: 新开一个 Cursor Tab,切换到 Gemini Pro 2.5(因为它处理完整的代码库扫描更胜一筹),让它全面检查代码库 (codebase),并核对 Story (实施计划) 的完成情况,然后同步更新 Story 状态。
重要提醒: 即便像 Claude 3.5 Sonnet 这样的模型在执行代码生成时表现出色,它也可能“自认为”完成了所有任务。因此,你需要一个拥有更大上下文窗口的模型(如 Gemini 2.5 Pro)来检查整体任务进度,确保一切符合预期,并指出差异。同时,当你在 AI 生成的代码基础上进行修改时,务必同步更新 Story 文档,避免大模型后续处理时发生记忆错乱或信息丢失。
请记住:Story (实施计划) 是你唯一可以完全信任的上下文参考。
使用 Gemini 2.5 Pro 进行代码审计和 Story 核对:

结语
通过建立清晰的“上下文边界”——也就是这套结构化的文档体系——我们可以有效地引导 AI 编码工具,最大限度地减少幻觉、错误循环和情境理解偏差。这不仅能让 AI 更可靠地辅助我们开发,更能显著提升整体开发效率和项目成功率。希望这套“上下文边界方法”能对你有所启发!
最后这是赛博程序员赵师傅给你整理的干货,如果觉得还不错,可以顺手点个关注~