ComfyUI重大更新:原生API节点可以编排生成任务
ComfyUI 今天隆重推出了一项革新性的功能——“原生 API 节点 (Native API Nodes)”。这项新特性允许用户在其熟悉的工作流界面内,直接整合并调用众多主流的付费模型 API。目前已支持包括 Google Veo2、OpenAI GPT-4o image、Stability AI、Luma、Recraft、Pika 2.2、PixVerse、Ideogram 在内的 11 个模型系列,共计 65 个独立节点。
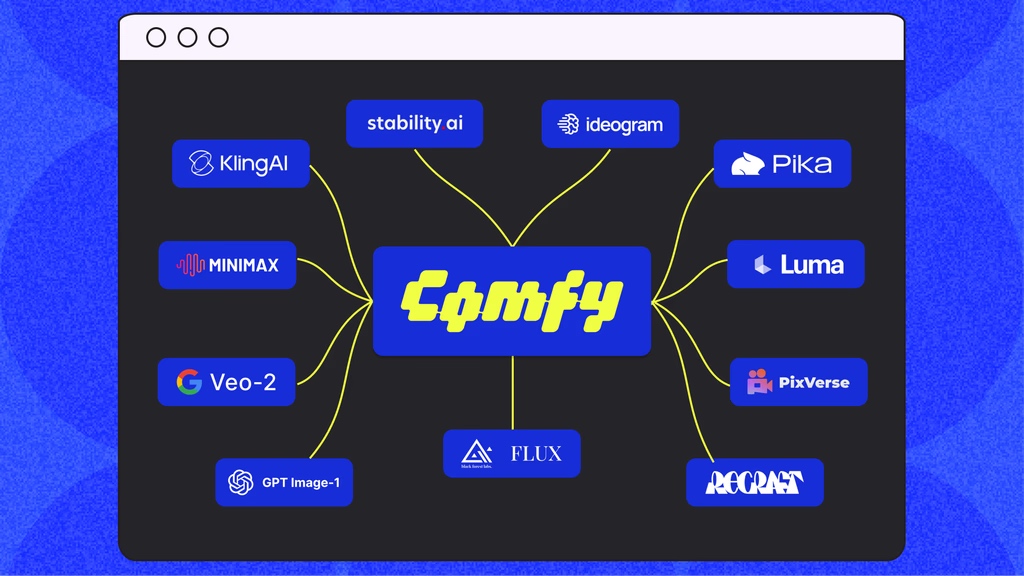
此举意味着,用户如今可以在单一的 ComfyUI 工作流程中,高效并行地调用图像生成、视频创作乃至文本转视频等多种类型的AI模型。整个过程无需离开当前操作界面,实现了生成任务的统一化编排与管理。
除上述核心功能外,ComfyUI 本次更新还带来了以下重要支持:
- 用户自持 API 密钥:允许用户沿用其在各外部平台已有的账户与API key。
- API 请求并行处理:显著提升同时调用多个模型时的执行效率。
- VIDEO 类型首次支持:实现了对原生视频生成任务的直接处理。
- 全新的 UI 视觉体系:融合了90年代动漫美学与Y2K科技潮流的设计风格,焕新用户体验。
值得强调的是,所有新增的 API 节点功能均为可选模块,ComfyUI 的核心本体依然保持其完全免费且开源的特性。
深入理解:ComfyUI 原生 API 节点
在本次更新之前,ComfyUI 主要作为一款以图形化节点驱动本地图像生成的工具,在 Stable Diffusion 用户群体中享有盛誉。而此次引入的“原生 API 节点”组件,则赋予了 ComfyUI 一项全新的核心能力:
原生 API 节点 (Native API Nodes):
用户无需编写任何代码,也无需切换至其他平台,即可在 ComfyUI 环境内直接调用一系列主流的“外部付费大模型 API”。
这标志着用户可以在一个统一的工作流中,灵活地组合和调度多种商业级 AI 模型(涵盖图像、视频及多模态应用),从而实现创作效率的大幅跃升。
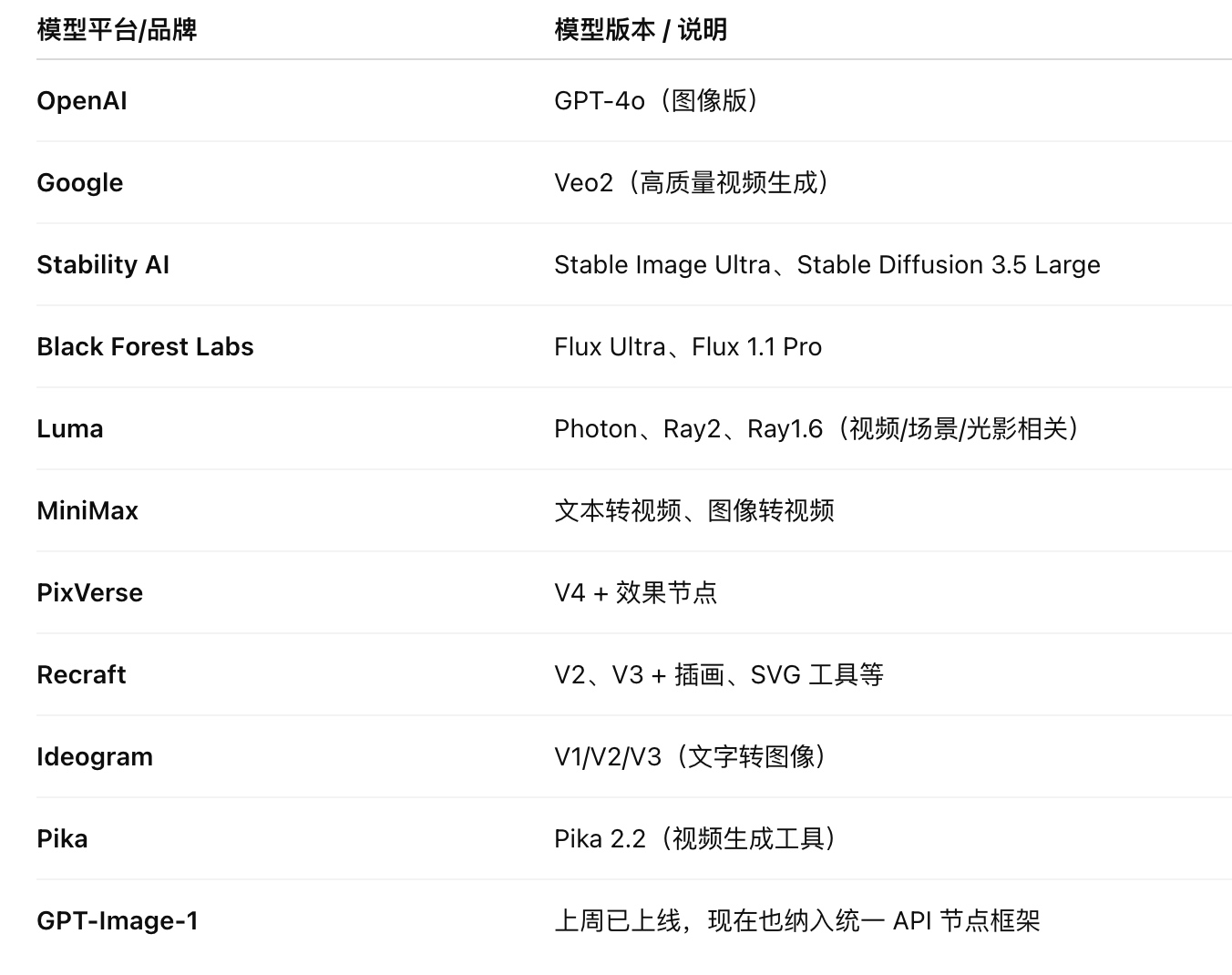
当前支持的模型与 API 概览
ComfyUI 新增了对以下 11 个知名模型系列的原生接入支持,总共提供了 65 个精心设计的节点,全面覆盖了图像处理、视频生成、文本转视频以及图像转视频等多样化的多模态任务。
重点支持模型包括:
用户仅需通过简单的拖拽操作即可调用这些模型的强大功能,无需逐一登录各个平台账户,并且支持将不同模型的节点组合使用,构建复杂的生成流程。
工作流中的实际应用指南
基本使用流程:
- 确保您的 ComfyUI 或 ComfyUI Desktop 已更新至最新版本。
- 登录或注册 ComfyUI 账户,购买新的 API 积分或绑定您在其他平台已有的 API 凭证。
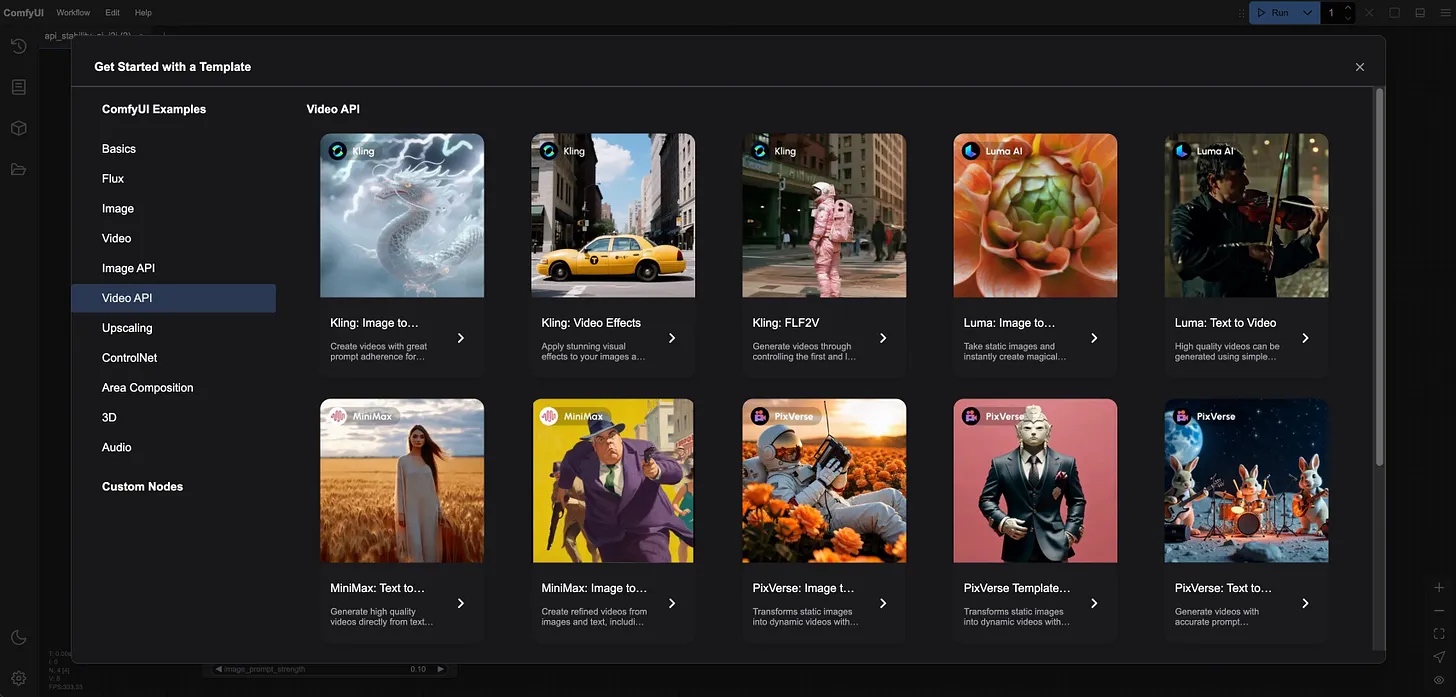
- 在菜单中选择:Workflow → Browse Templates → Image API / Video API。
- 选取合适的模板即可直接运行,或以此为基础进行修改。
此外,用户亦可选择“自带 API 密钥 (Bring Your Own API Key)”模式,将您在 Pika、Luma、OpenAI 等平台上已有的订阅或额度与 ComfyUI 进行绑定。
支持高效的并行执行:
当工作流中涉及调用多个外部 API 时(例如,一个任务同时需要图像生成、视频合成及字幕添加),ComfyUI 会自动并行处理不同节点的请求,从而显著缩短整体的生成时间。
一个典型的多模型协作示例如下:
- 输入文本 → 利用 GPT-Image API 生成初步的人物素描。
- 素描图像 → 接入 Luma Photon API 增强真实感光照效果。
- 场景图像 + 提示词 → 通过 PixVerse API 生成动态视频片段。
- 视频片段 + 描述文本 → 调用 Pika API 生成带有动画和对白的镜头。

首次引入对 VIDEO 类型的原生支持
本次更新是 ComfyUI 发展历程中首次实现对“视频生成”类型节点(VIDEO类型)的原生支持,这具有里程碑式的意义:
- ComfyUI 的能力不再局限于静态图像任务。
- 为构建复杂的视频-图像混合型工作流提供了可能。
- 支持跨模态协作,如图像到视频的转换、视频生成后再进行片段提取与重构等高级应用。
- 为未来进一步整合音频处理、3D模型生成等节点扩展奠定了坚实基础。
视觉与品牌形象的全面革新
除了核心技术功能的显著增强,ComfyUI 也正式发布了其全新的品牌视觉识别系统:
- 全新 Logo:设计由多个模块化单元构成,巧妙呼应了其“节点化图形工作流”的核心特性。
- 字体与配色方案:大胆融入了90年代经典动漫风格与Y2K数字美学元素,营造出独特的视觉感受。
- 品牌理念传递:在保留“自由、可拓展、可探索 (Hackerable)”的社区精神基础上,更加强调了 ComfyUI 作为一款专业工具的强大性与创作过程的开放性。
官方阐述如下:
“我们希望传达这样一个信息:ComfyUI 依然是那个自由、开放的平台。与此同时,它也已演进成为一款真正能够融入生产级流程的强大工具。”

核心价值亮点总结
-
统一化的多模型集成平台: 在一个工作流中无缝整合多个主流 API 的调用能力,彻底告别在不同平台间切换、手动上传下载素材的繁琐操作。
-
免费核心与可选商业API的灵活组合: ComfyUI 主体程序持续开源免费,新增的 API 节点则根据用户需求按需选用。这既保障了创作者的自由度,也提供了接入商业级顶尖模型的能力。
-
真正面向创ポーター的“多模态生成管线”: 实现了图像、视频、文本、结构化数据以及风格化处理的统一融合,并为未来集成音频、3D 等更多类型的节点预留了广阔空间。
新功能的目标用户群体:
- 各类图文内容创作者(例如微博博主、公众号运营者、短视频配图制作者)。
- 专业的 AI 视频编辑人员(特别是 Pika, Veo2, PixVerse 等工具的现有用户)。
- Stable Diffusion 的高级玩家(希望将其他模型的优势融入现有工作流的用户)。
- 设计师及广告创意从业者(需要进行多种图像风格混搭与生成)。
- 教育内容开发者(例如需要将视频素材转化为图文教程,或为视频匹配 AI 生成的动画)。
- 产品经理与应用程序开发者(需要快速构建和验证 AI 驱动的工作流原型)。