今天科普一个新知识:大模型思维链(CoT),保准让你5分钟搞懂学术黑话,还能用它搞定课程作业!
TLDR. 字数约2000字,阅读5min,建议深度研读相关论文和辅助知识文档
0x00 为什么AI突然会”思考”了?
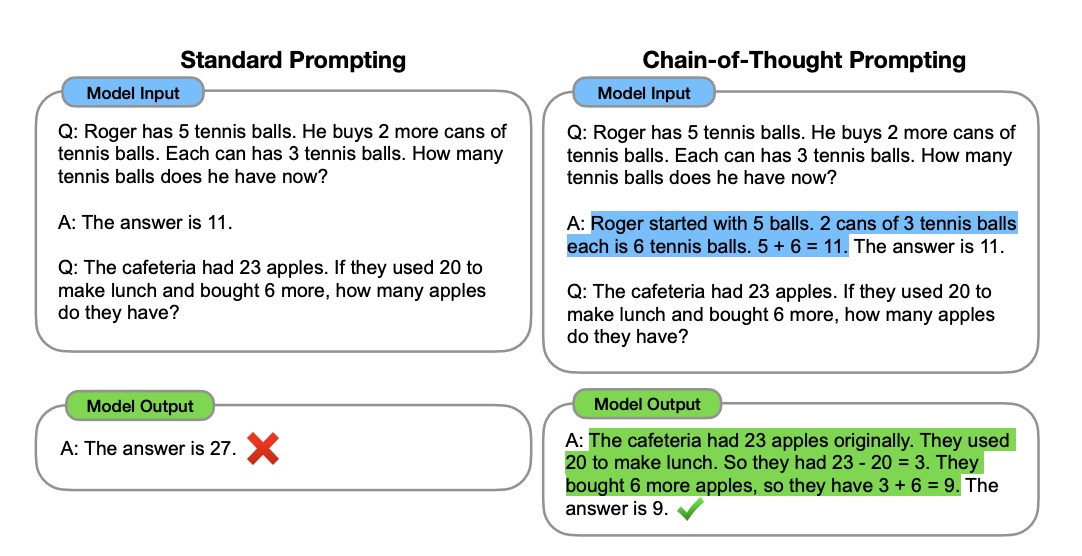
以前 ChatGPT 或者各种对话形态的大模型做数学题还像小学生,今年 Deepseek 横空出世能解微积分了并且还能让我们看到思考的过程,这是为啥?这都要感谢思维链技术!就像你解数学题要写步骤,AI现在也要”打草稿,想一想,然后给答案”了!
举个栗子🌰:
问:小明买5个苹果花了30元,买3个橘子花了18元,哪个更贵?
老版AI直接蒙圈,新版AI会这样想:
1️⃣ 苹果单价=30÷5=6元 2️⃣ 橘子单价=18÷3=6元 3️⃣ 结论:价格相同
ok,严肃起来
0x01 什么是 CoT ?
核心定义:
思维链(Chain-of-Thought,CoT)是由Google Research团队在2022年提出的革命性技术(论文地址:arXiv:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models)。其核心是通过显式生成中间推理步骤,将传统输入-输出的”黑箱”过程转化为可解释的思维链条。
一个完整的包含 CoT 的 Prompt 往往由指令(Instruction),逻辑依据(Rationale),示例(Exemplars)三部分组成。一般而言指令用于描述问题并且告知大模型的输出格式,逻辑依据即指 CoT 的中间推理过程,可以包含问题的解决方案、中间推理步骤以及与问题相关的任何外部知识,而示例则指以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题,推理过程与答案。
通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能。而这些推理的中间步骤就被称为思维链(Chain of Thought)。
主要结论:
- 大模型上更有效,在小模型上能会产生流畅但不合逻辑的思维链;
- 在复杂问题上更有效,只需要一步两步推理过程的任务,没有效果;
- 在算数、常识推理和符号推理上均有效果。
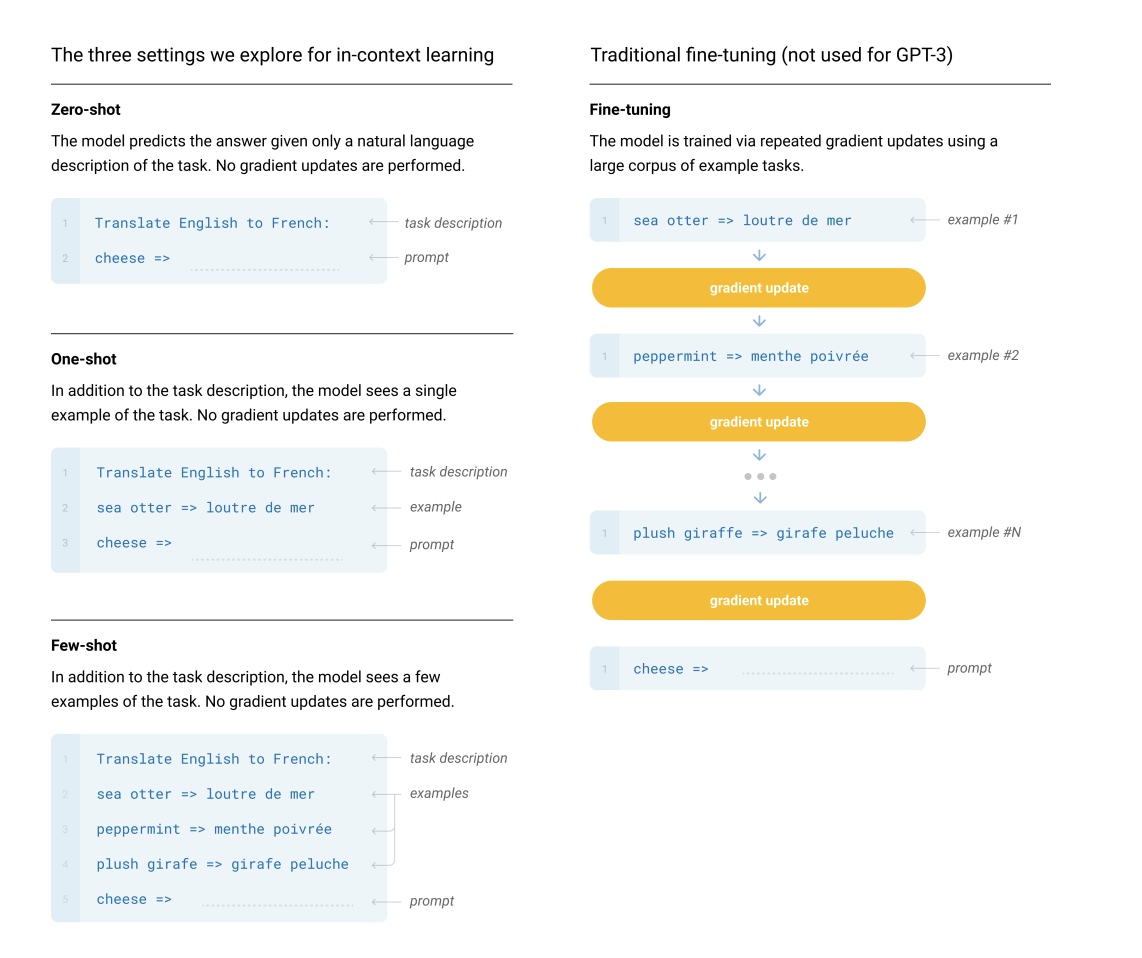
更早的是 OpenAI 就在论文 Language Models are Few-Shot Learners 中提出了如何使用 prompt learning 提升大模型的推理能力。论文中提出了 Zero-shot、One-shot、Few-shot 三种不同的 prompt 方法,如下图所示
Few-Shot(FS)是指模型在推理时给予少量样本,但不允许进行权重更新。 One-Shot(1S)与 Few-Shot 类似,只允许一个样本(除了任务的自然语言描述外)。 Zero-Shot(0S)和 One-shot 类似,但不允许提供样本,只给出描述任务的自然语言指令。
Zero-shot CoT: 是目前体验最好的跟大模型对话方式!
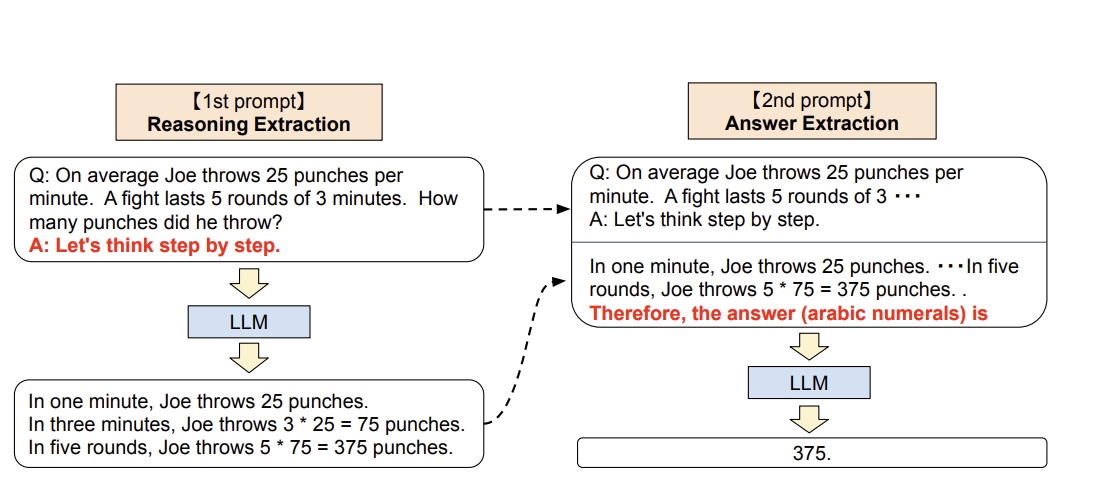
最早的一篇文章 arXiv:Large Language Models are Zero-Shot Reasoners,提出了 Zero-shot 模板的方式,来提高大模型的推理能力,原文中是一个2阶段的流程,reasoning extraction -> answer extraction,如下图所示
Zero-Shot-CoT 不添加示例而仅仅在指令中添加一行经典的“Let’s think step by step”,就可以“唤醒”大模型的推理能力。
流传的最广的”Let’s think step by step.”,是效果最好的(简单才是核心杀手锏)
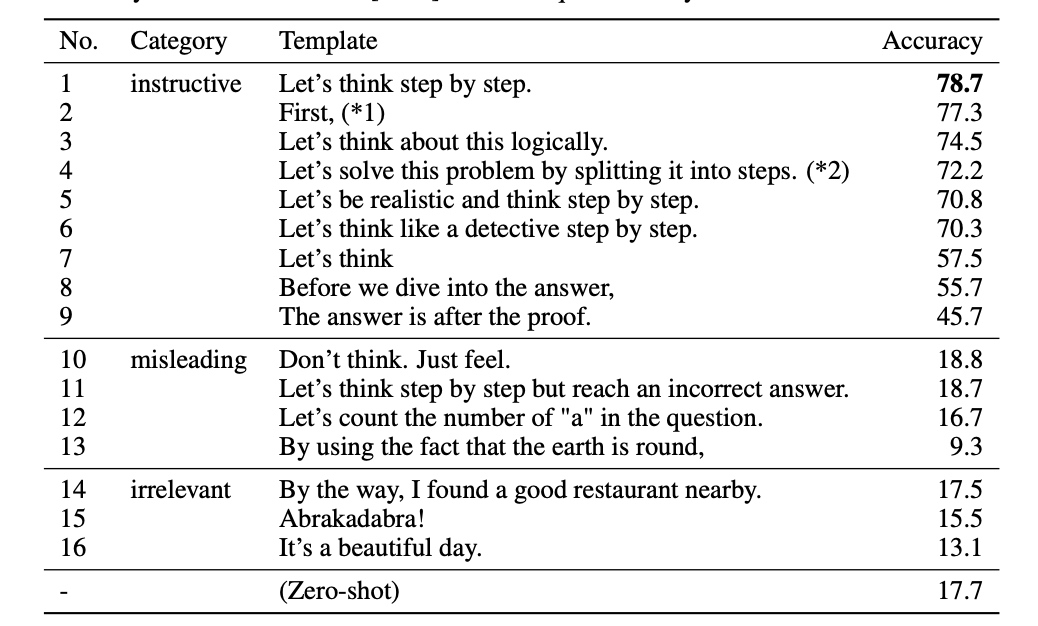
你也可以参考还有这些提示词,有类似的效果:
- “Let’s think step by step.”
- “First, Let’s think step by step.”
- “Let’s think about this logically.”
0x02 CoT 应用
CoT 提示过程是一种最新的的提示词方法,它提示大语言模型解释其推理过程。思维链的主要思想是通过向大语言模型展示一些少量的 exapmles,在样例中解释推理过程,大语言模型在回答提示时也会显示推理过程。这种推理的解释往往会引导出更准确的结果。
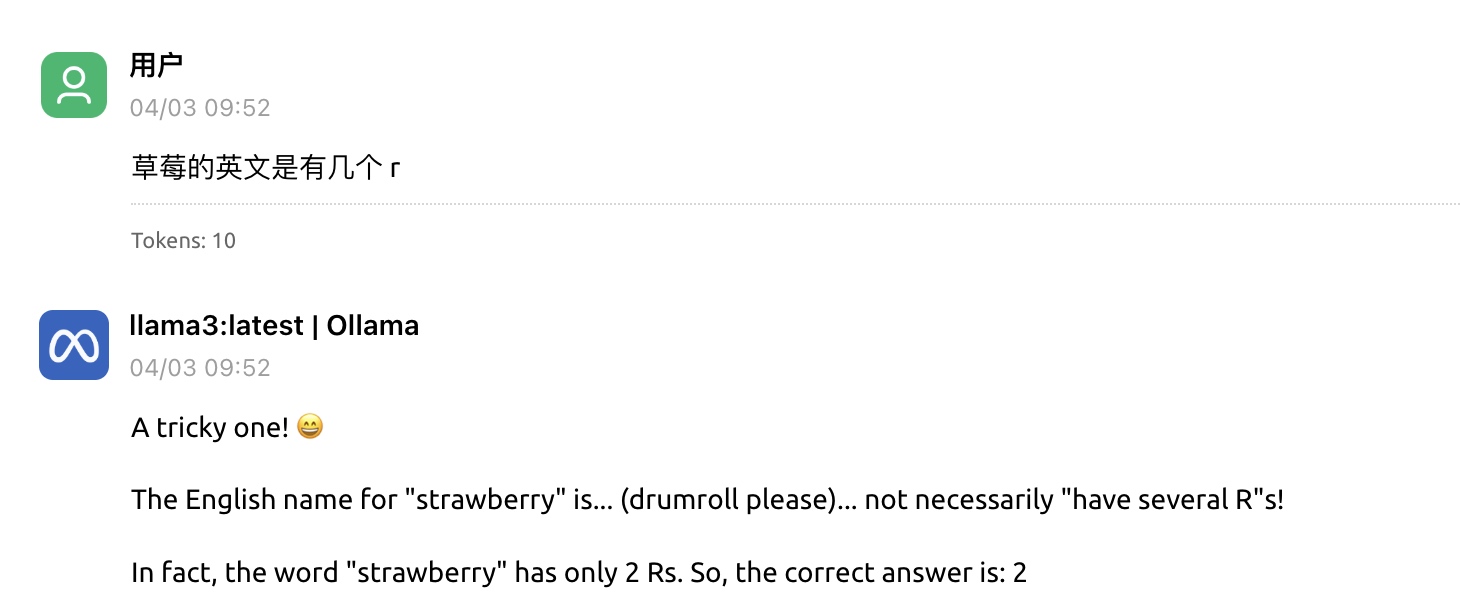
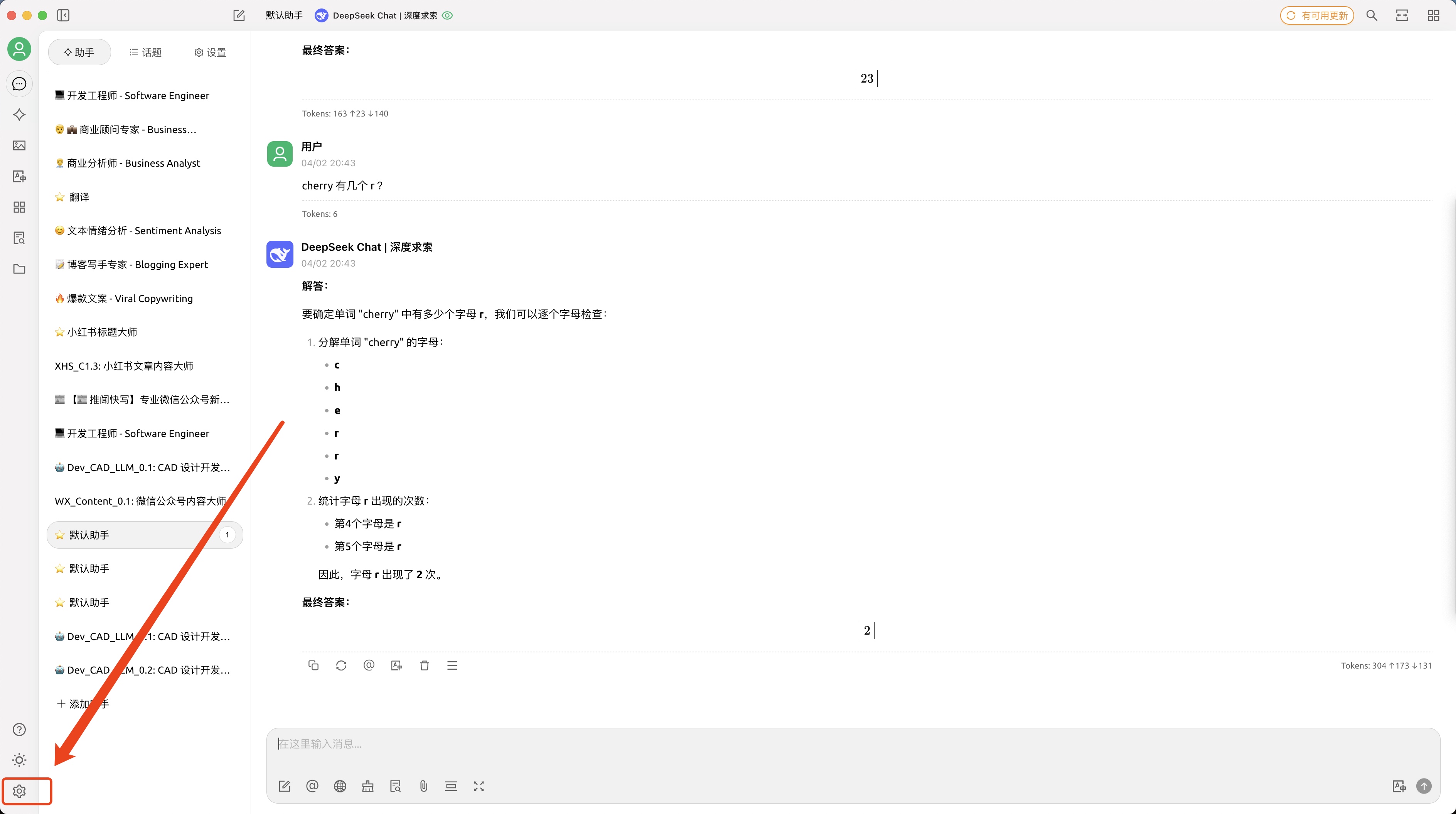
我们看一个没有 CoT 的模型解答这个问题:
草莓的英文是有几个 r
我们本地部署的一个超级年轻版本(—古董): llama3:latest 回答真是有趣🤔(错误)
加入 CoT 提示词:
Let’s think step by step. 草莓的英文是有几个 r
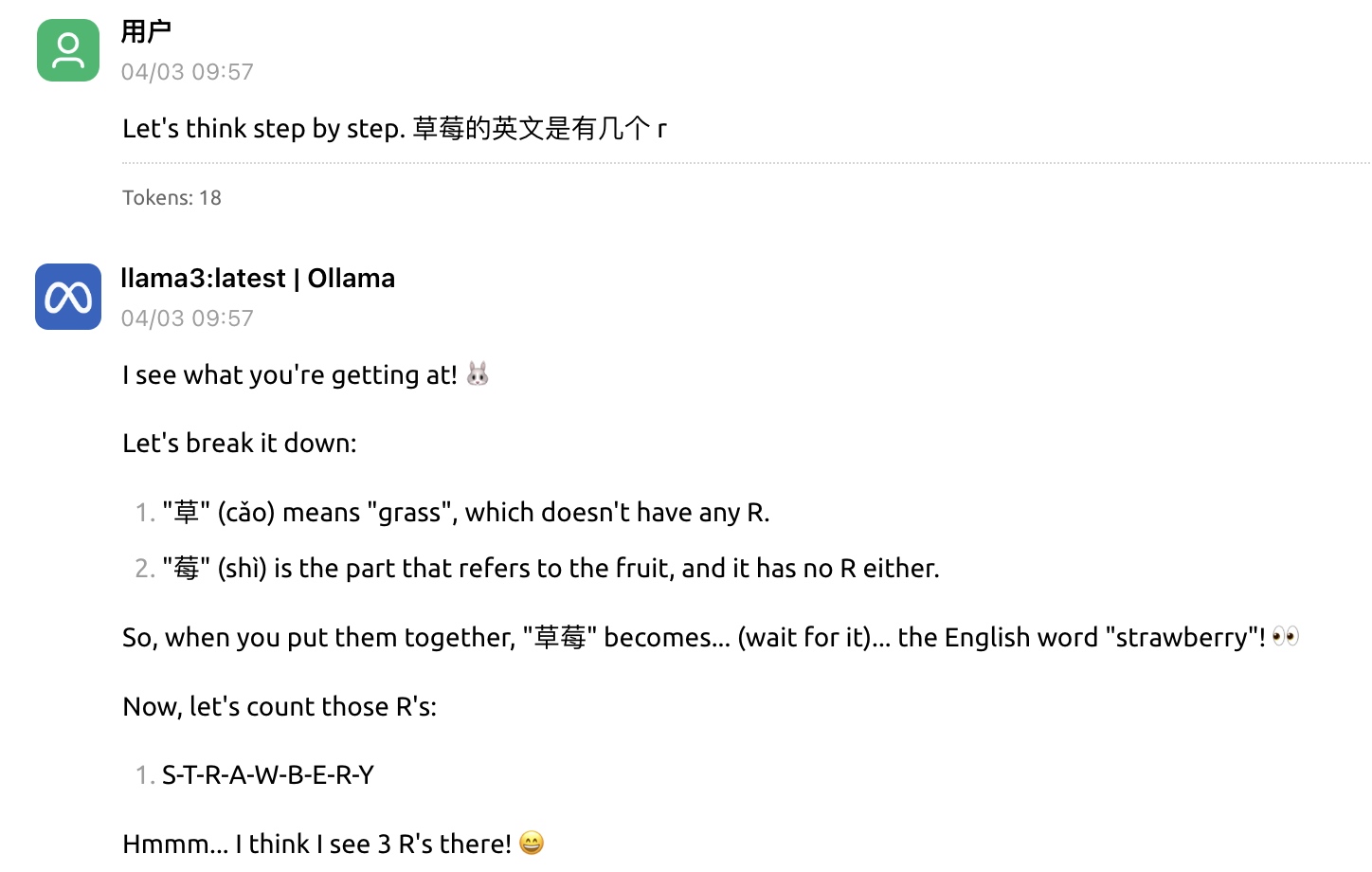
CoT 可以显著提高语言模型的复杂推理能力体现的核心几个点:
- 拆解问题: 和人一样将复杂问题拆解为多个子问题进行求解,降低求解问题难度。
- 提供步骤: 思维链会给模型提供引导步骤,演示推理过程
- 强化逻辑: 模拟人类思维逻辑步骤,提升模型推理逻辑能力
- 可解释性: 引导模型输出思考过程,方便人类理解隐含层和进行互动调试
- 适应性强: 思维链不局限场景,适配任意文本到文本场景,不用微调,也可大大减少数据标注需求
CoT 仍然存在不足:
- 幻觉问题没有解决,生成的思维链不一定准确,需要更多改进和严谨事实的步骤
- 思维链更适配大参数模型,参数规模小模型提升有限,大参数模型使用价格昂贵
- 思维链严重依赖提示词,结果变化大,需要探索稳定效果的提示方法或者全新范式
Chat 云应用
大多数目前主流的 Chat 类大模型应用,哪怕不是推理模型,基本上都是已经内置了 Let's think step by step. 提示词提升效果,因此你加不加 CoT 提示词效果都不明显
直接使用吧~
大家都看厌了 openai,我给大家强烈推荐狗家的 Gemini,不仅便宜,能力还是杠杠的。Gemini 2.5 已经在各大榜单屠榜,2.x 系列基本都是超强能力模型,而且你不用掏钱啊!!!
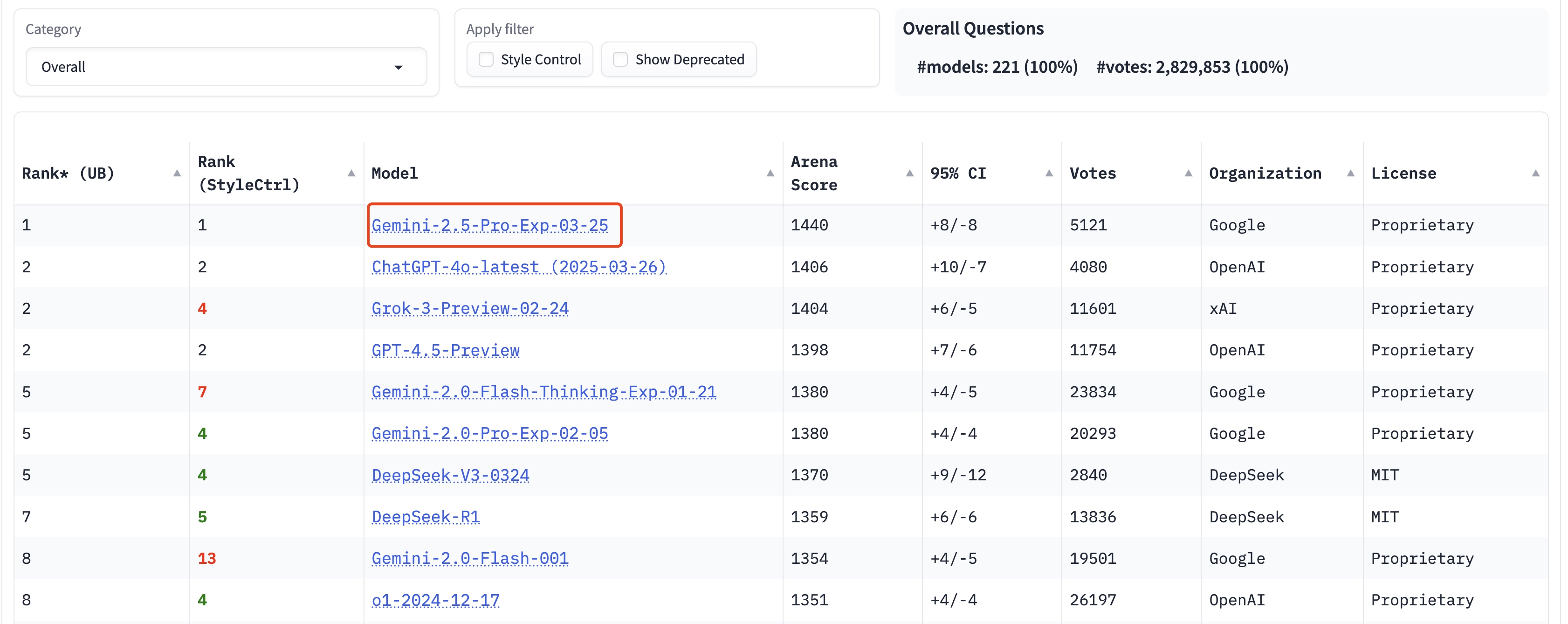
Let’s Go to Google AI Studio 一探究竟
step1: 微 Do 一个系统提示词吧~
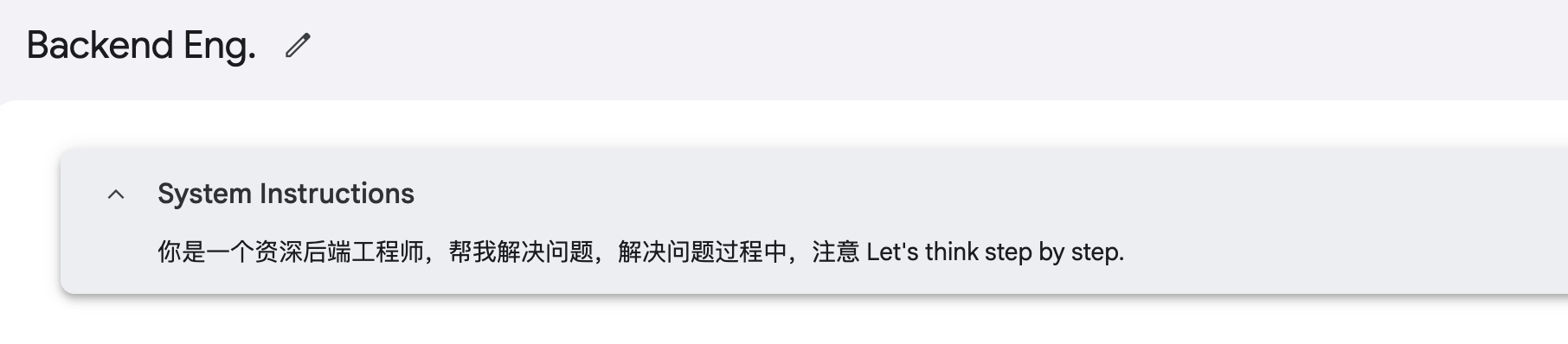
step2: 给大模型一点厉害,问个我自己都很纠结的问题~
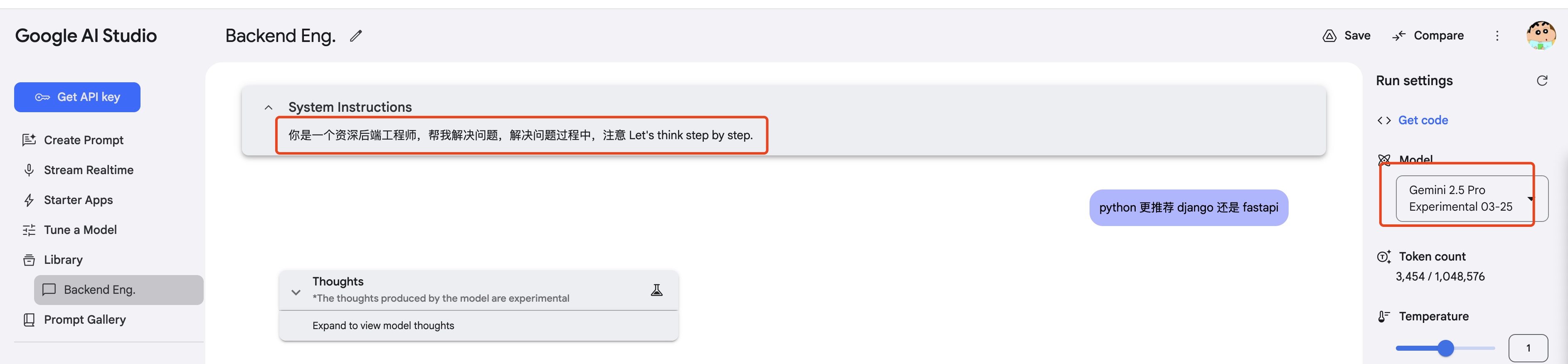
show time ~
thought: 思维链已经超越了 90% 的 python 初级开发,不仅思考用户需求、技术栈差别,还会结合用户背景进行组合提示对比分析,这不就是一个严谨的架构师思维吗~ (思考过程太长,不截图啦)
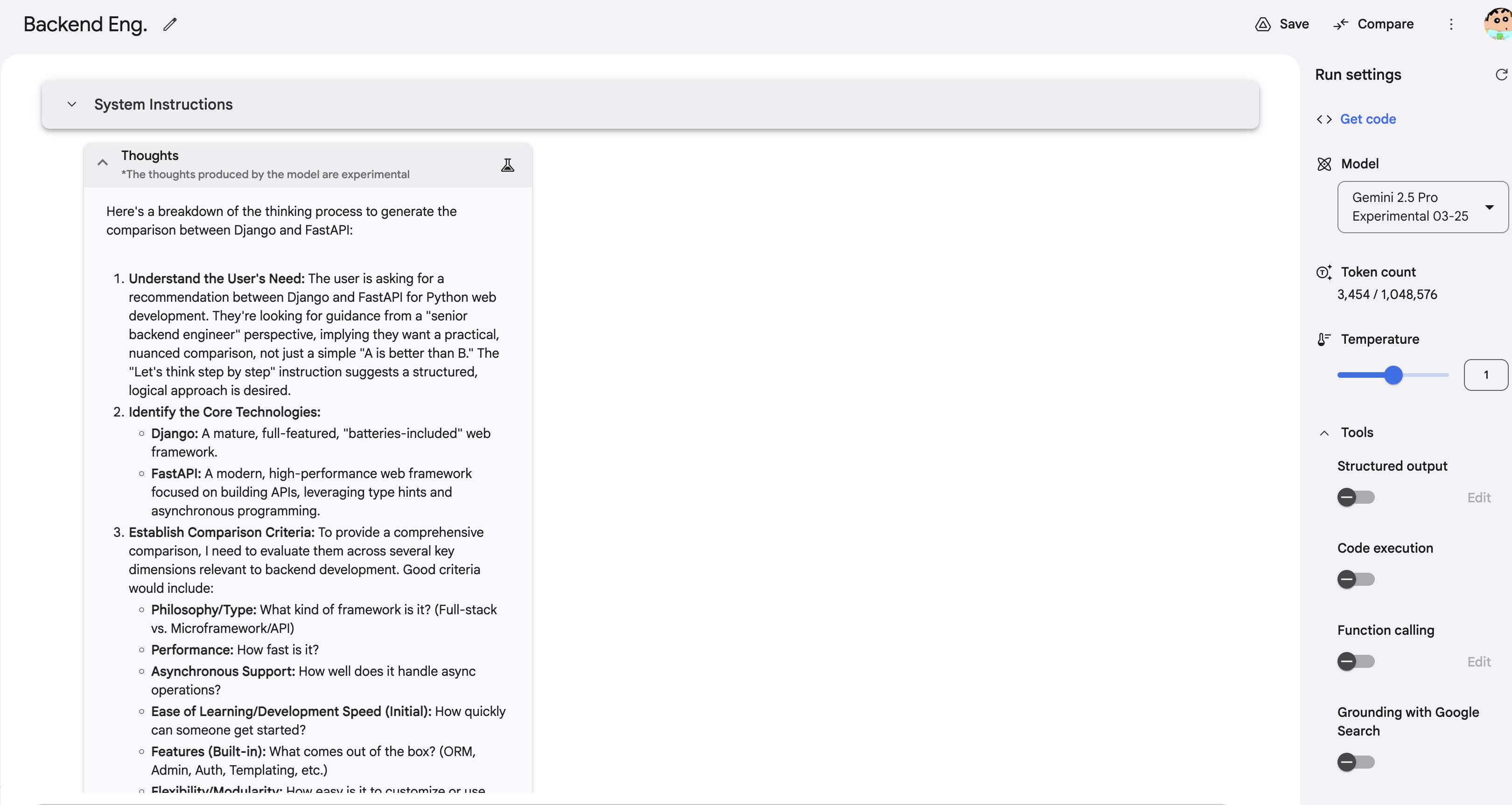
answer: 一步一步给出说明,最后总结适用场景。你完全可以补充你的背景、关键需求、技术栈,大模型会进一步给出推荐。(太强了,以后我看大厂八股文怎么面这题 :)


Chat 本地应用
云应用虽好,但是有很多问题没办法,一些场景只能在本地跑跑~
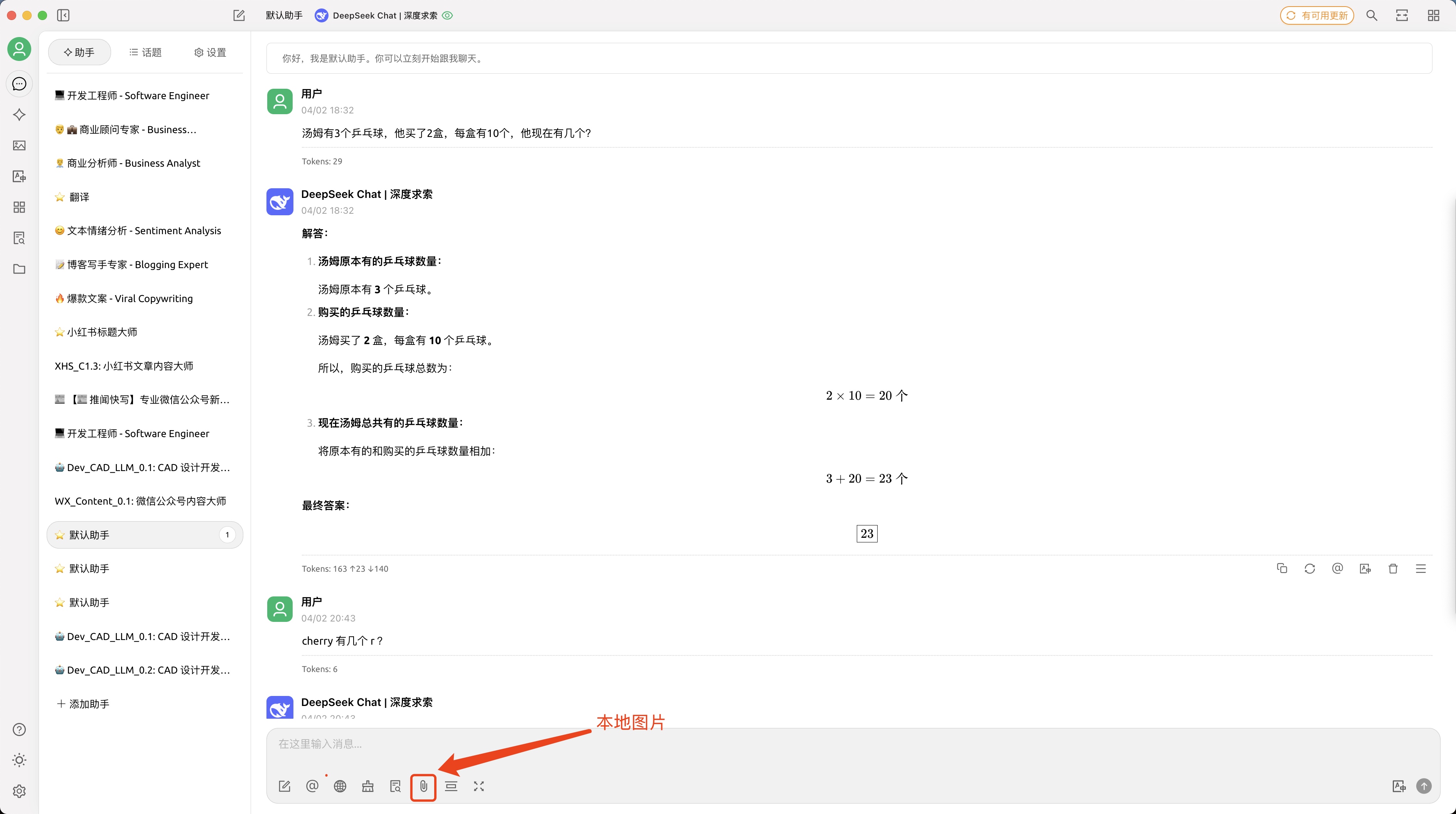
这个时候我推荐 CherryStudio 啦啦啦,这是我用的最多的 Chat LLM App,是一款支持多模型服务的桌面客户端,对 OLLAMA 友好,集成各类 API 供应商方便,还一个场景能打开很多对话大模(ChatGPT/Gemini/DeepSeek/Kimi…) 👍
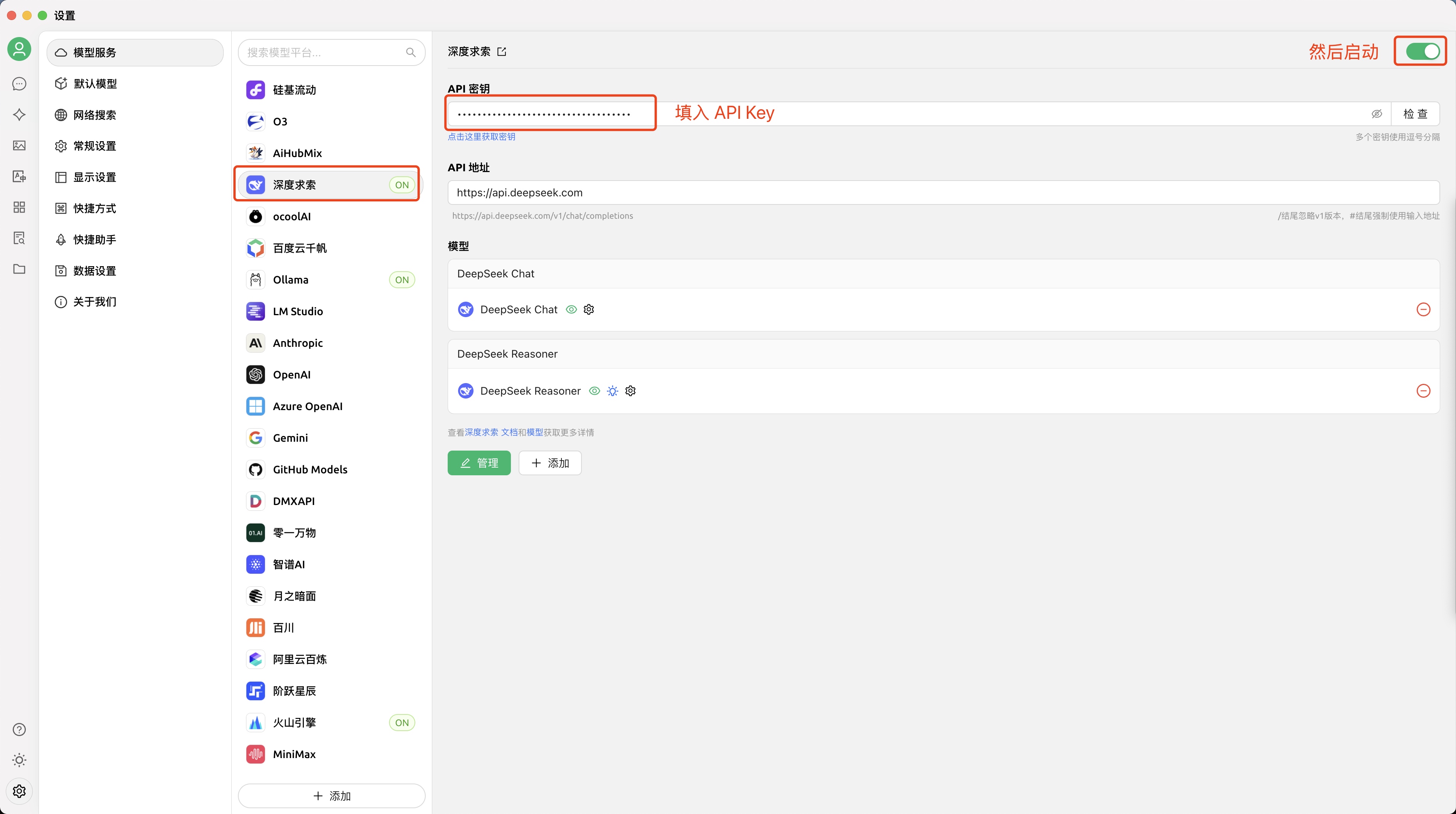
下完 App,我们要想使用大模型,还是需要做一步 “API 密钥获取与配置”
API 密钥获取与配置
最方便的肯定是直接奔着DeepSeek 开放平台去啦,很多厂商提供的太复杂了,头都晕了
step1: 点开 👉 DeepSeek-开放平台 之前充值过的,肯定有用量和余额,可以跳过 step2
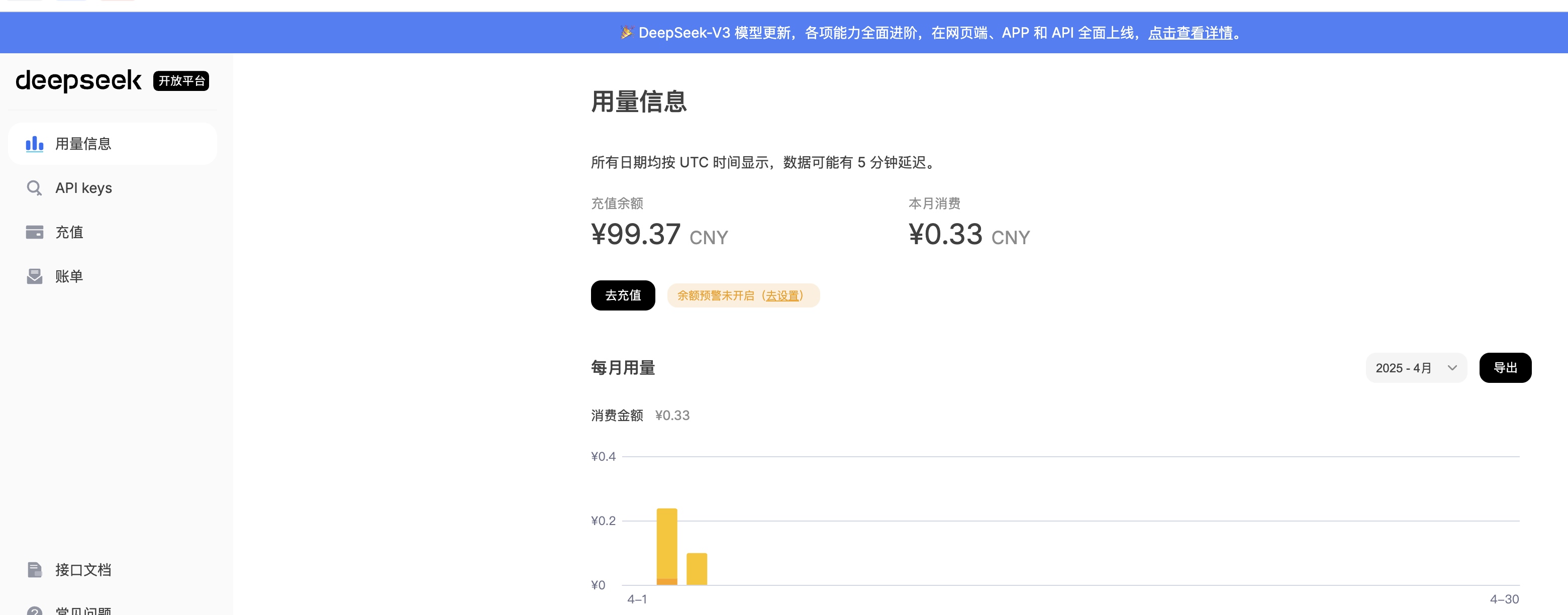
step3: 点开 👉 DeepSeek-充值 (流下贫穷的泪水,咱只配用 100 块。。。 其实 10 块已经可以用很久了 (我不信你不会用蓝绿修改器,这个我珍藏,不教~ 充值回来看看你的余额吧~
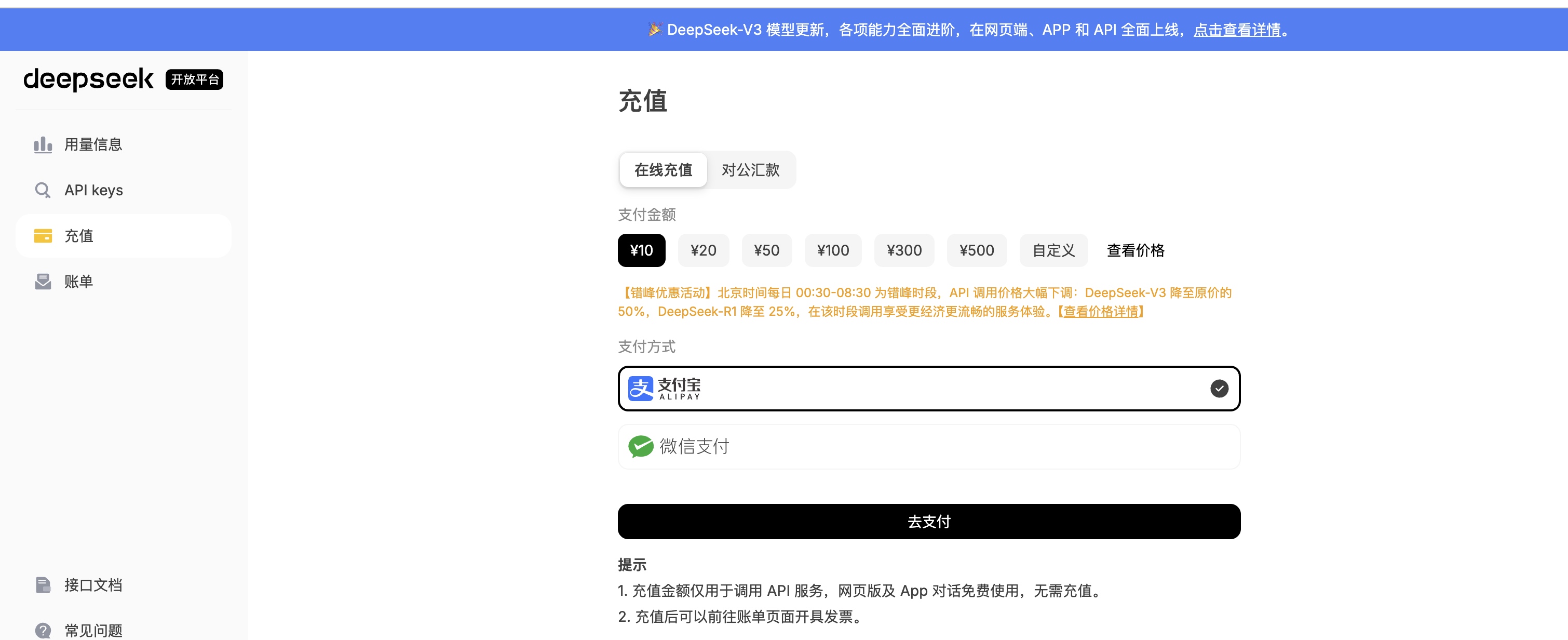
step2: 点开 👉 API keys 建议1: 输入有明确场景的名称,例如 MyPC_CHERRY_STUDIO 建议2: 生成的 API Key 珍藏、珍藏、珍藏、不要泄漏给别人
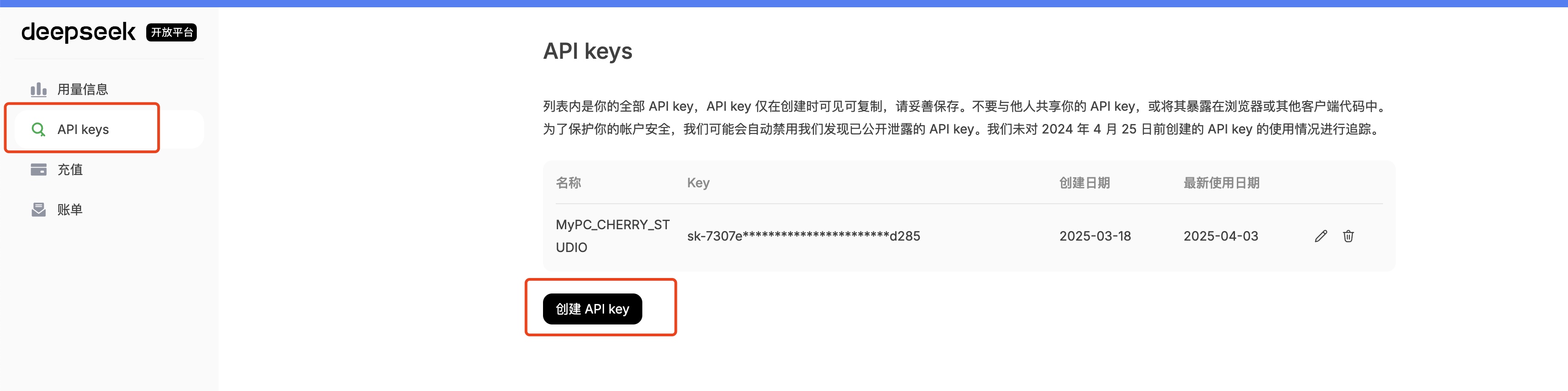
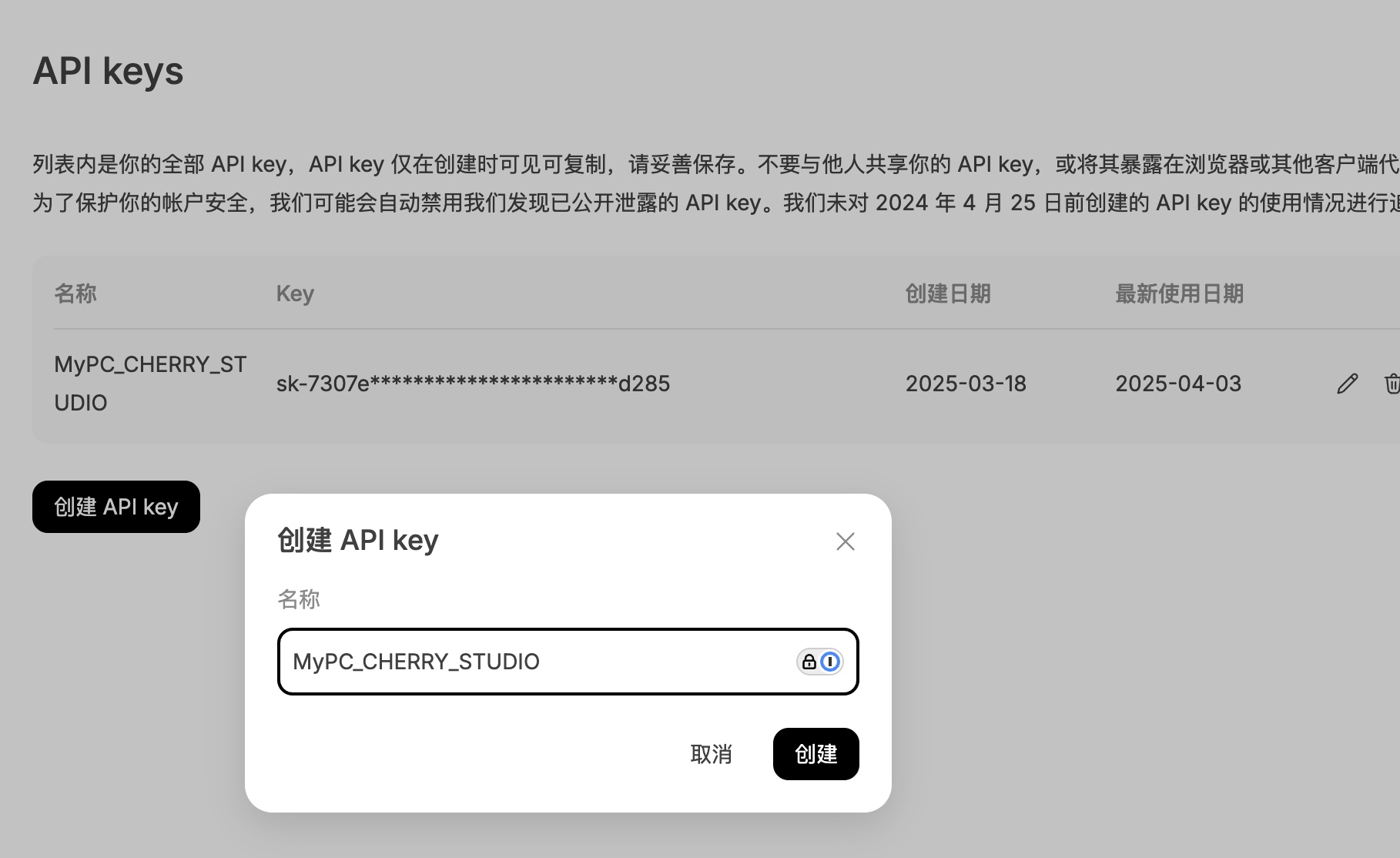
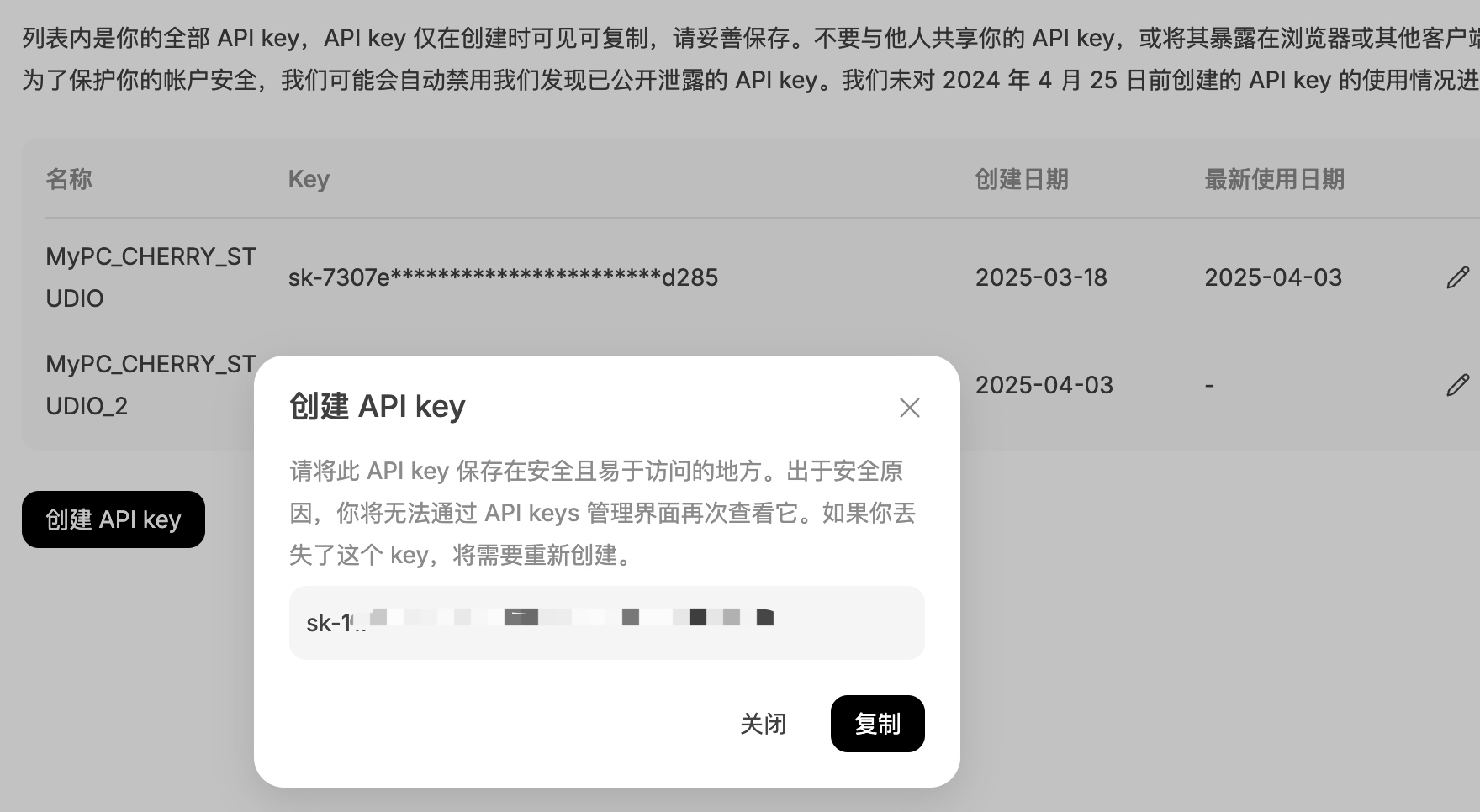
OK,已经拿到 API Key,后面就是非常简单的使用啦~
step4: 配置到 CherryStuio 的 DeepSeek 大模型
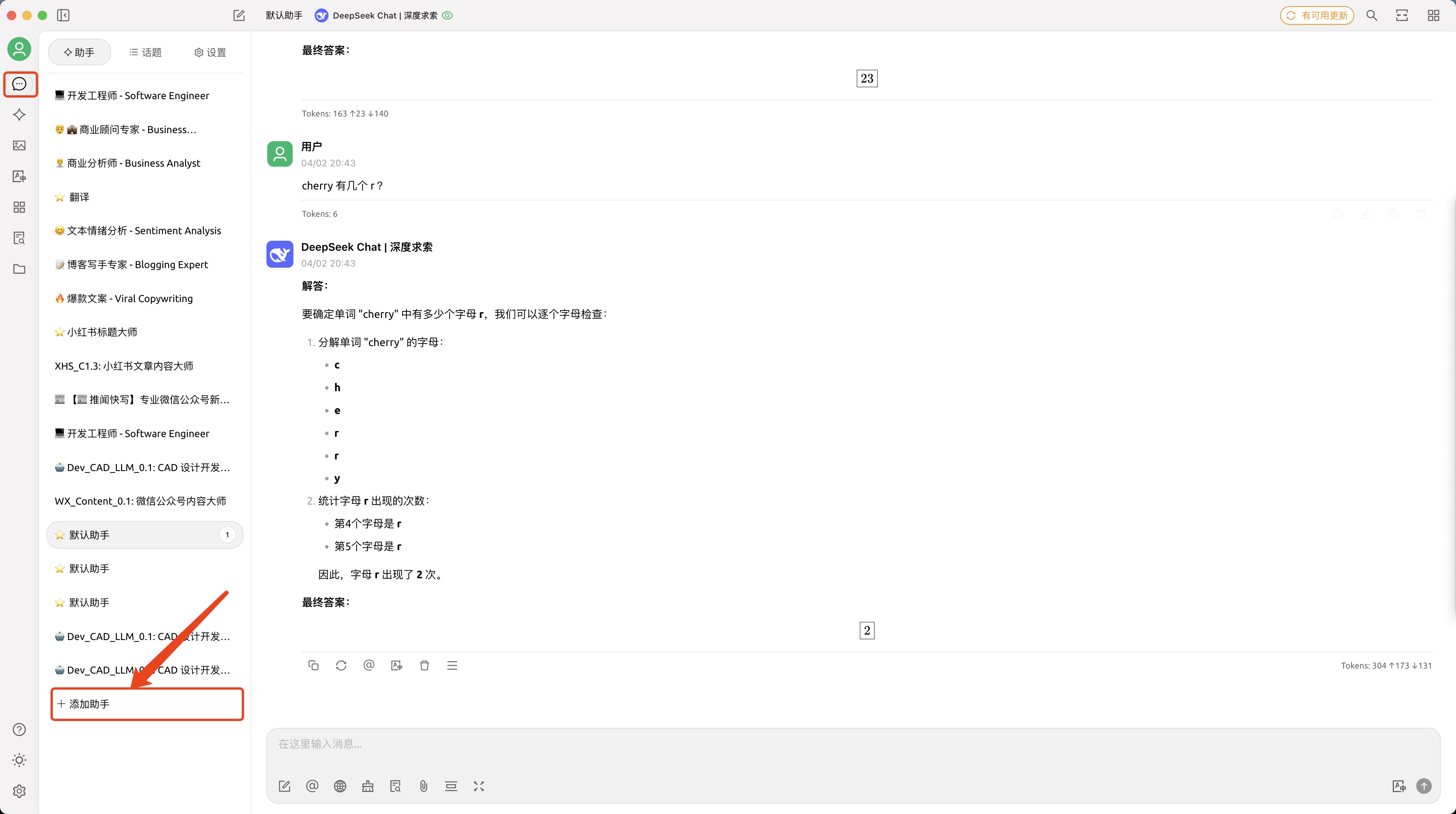
开启 - AI 助手与对话
step1: 点对话图标,点添加助手 助手太多啦,本质上就是系统提示词不一样,使用是一样的,后面我写文章记录提示词的差别和场景吧
step2: 输入你的问题,开启对话~